Overview
The Problem
Consultants lose knowledge between projects. Every engagement generates insights - emerging trends spotted in client conversations, academic papers that explain phenomena, frameworks that worked well, patterns that keep appearing across industries. But this knowledge scatters: browser bookmarks with 200+ tabs never revisited, notes in project folders forgotten after handoff, mental models that fade without reinforcement, research done twice because you forgot you already found it.
The Solution
A consulting OS that captures knowledge as you work -- and then organizes itself. Field Kit started as a personal RAG system built on three principles: (1) Selfish software - build for your own needs first, (2) Minimal friction - add knowledge in the flow of work, not as a separate task, (3) Compound returns - every signal, paper, and insight you capture makes future work easier. It grew a fourth: (4) Self-organization - the system tracks what gets retrieved, what gets used, and what gets used together, then runs a weekly "dreaming" loop that names the emerging patterns. MCP (Model Context Protocol) servers integrate it directly with Claude Desktop, Claude Code, and a Telegram bot. No context switching to separate apps.
The Challenge: Knowledge That Compounds
Traditional knowledge management tools fail because they optimize for the wrong thing. They make it easy to organize knowledge but hard to capture and retrieve it.
The Friction Problem
What Consultants Need:
- • Capture insights without breaking flow
- • Search semantically, not with keywords
- • Discover unexpected connections
- • Knowledge that compounds over time
What Traditional Tools Offer:
- • Manual tagging and organization
- • Keyword search (misses connections)
- • Separate apps (context switching)
- • Static databases (don't learn)
The gap between how knowledge workers think (associatively, across domains) and how tools work(hierarchically, in silos) creates friction at the worst moment - when you need the insight for a client deliverable.
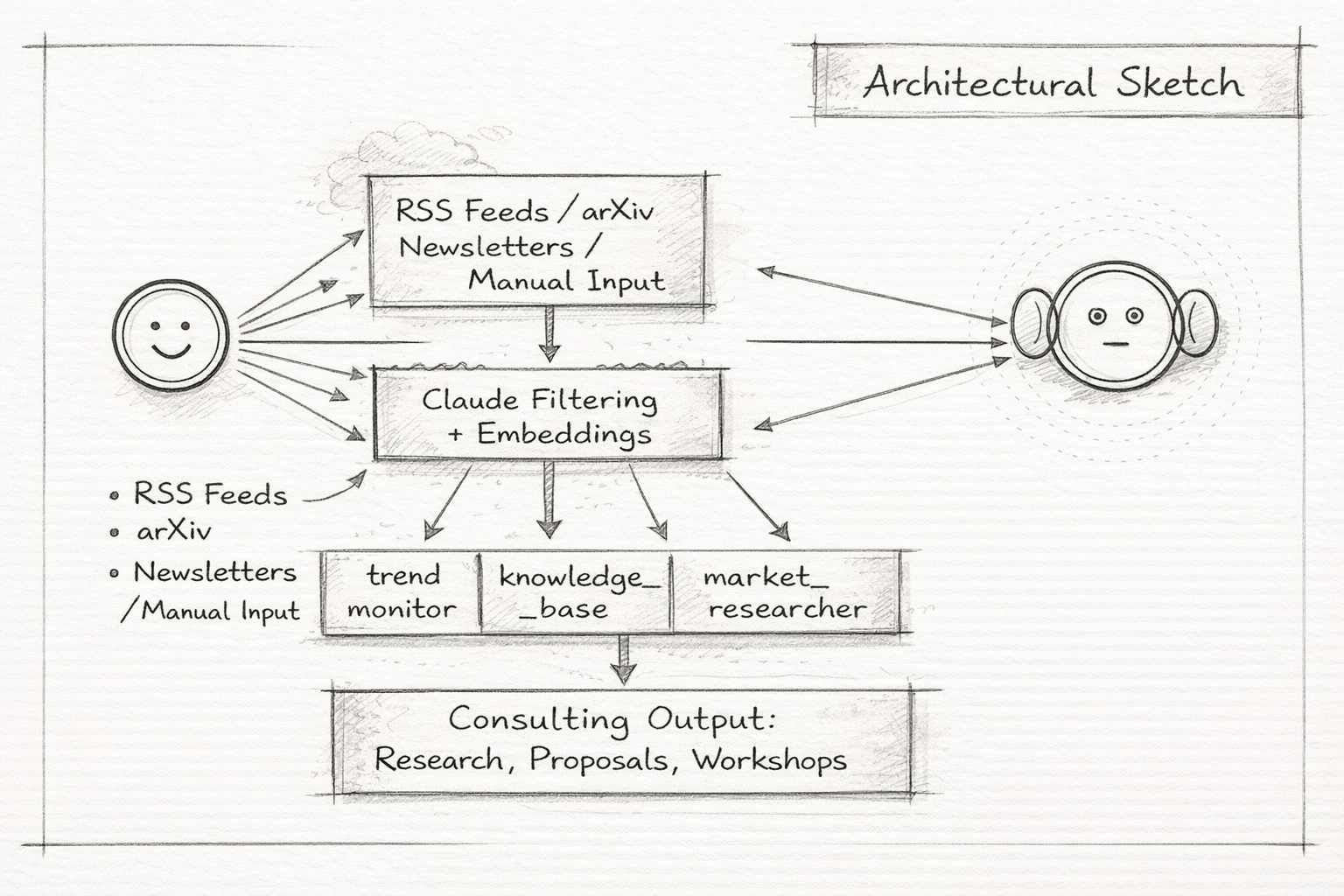
The Architecture: 4 MCP Servers, 70+ Tools
Rather than building a monolithic app, I created specialized MCP servers that integrate with Claude Desktop, Claude Code, and a Telegram bot via an MCP bridge. Each server handles a different dimension of consulting intelligence:
MCP Server 1: trend_monitor (33 tools)
Purpose: Track and analyze emerging signals in AI, sustainability, and policy. Monitor academic research. Track regulatory developments. Synthesize patterns across domains.
search_trendsadd_trendanalyze_signalconnect_signalssearch_papersadd_paperadd_paper_manualanalyze_paperlink_paper_to_signalsearch_regulationsadd_regulationtrack_regulation_timelineanalyze_regulatory_impactlink_regulation_to_signalweb_researchparse_newsletterget_paper_full_textget_trend_statsUse case: Client asks "What's happening in AI regulation?" → Search trends for 4 EU AI Act signals → Cross-reference with search_regulations for specific articles → Run analyze_regulatory_impact for their use case → Answer in 90 seconds with citations.
Data: 267 trend signals, 216 academic papers, 10 regulatory provisions. Automated ingestion via GitHub Actions (arXiv RSS monitor daily, trend RSS monitor scheduled). Manual curation from client work and newsletters.
MCP Server 2: knowledge_base (21 tools)
Purpose: RAG over consulting IP -- frameworks, case studies, and methods. Proprietary knowledge that compounds over time.
search_frameworksget_frameworkadd_frameworksearch_casesget_caseadd_casesearch_methodssearch_knowledgeadd_methodget_methodget_kb_statsUse case: Client has change management challenge → search_cases finds 3 past projects with analogous situations → search_frameworks pulls methodologies that worked → Adapt approach with confidence, backed by real experience.
MCP Server 3: market_researcher (13 tools)
Purpose: Brand intelligence and competitive analysis. Merged from a standalone multi-agent market research tool into the Field Kit ecosystem, enabling unified semantic search across all knowledge domains.
search_brandsget_brand_contextadd_brandsearch_brand_reportsget_reportadd_brand_reportsearch_allcompare_brandslink_brand_to_trendget_competitorsget_market_statsUse case: Preparing competitive positioning for a client → search_brands for industry landscape → compare_brands on sustainability positioning → search_all to cross-reference with relevant trends and regulations.
Telegram Bot: Conversational Interface
Purpose: Mobile-first access to the full knowledge system. A Claude Sonnet-powered conversational agent with an MCP bridge that routes queries to all four servers. Supports Swedish and English, maintains per-user conversation history, and runs agentic tool-use loops (up to 10 iterations per query) for complex research tasks.
MCPBridgeSSE transportDynamic tool discoveryTool routingConversation historyUser whitelistUse case: At a conference, hear an interesting claim about AI regulation → open Telegram → ask "What do we know about AI Act Article 6 and high-risk classification?" → bot searches regulations, cross-references with trends, returns a synthesized answer with citations. No laptop needed.
Deployment: One Corpus, Three Sites
The same four servers run in three places, all sharing a single Supabase corpus: stdio locally for Claude Desktop and Claude Code, a Hetzner VPS running the Docker Compose stack (SSE endpoints on ports 8081-8084 with health checks) plus the Telegram bot, and a Mac mini running the MCP servers for an autonomous research agent. Add a signal from any surface and it is queryable from every other surface seconds later.
MCP Server 4: org_registry (6 tools)
Purpose: Organization canonicalization across the whole corpus. Brands, cases, and reports all reference organizations -- org_registry keeps one canonical record per org with aliases, so "Uppsala University" and "Uppsala universitet" resolve to the same entity instead of fragmenting the knowledge graph.
find_orgget_orglist_orgsadd_orgadd_aliasesmerge_orgsHow Field Kit Learns: The Five-Layer Organism
Most knowledge bases only grow. Field Kit also metabolizes: it notices what it uses, what it uses together, and what those together-things mean. The architecture is five layers, deliberately graded from SQL-cheap at the bottom to LLM-expensive only where reasoning is genuinely needed.
The Stack
Substrate. Supabase (Postgres + pgvector), 30+ migrations, Row-Level Security on every table. Trends, papers, regulations, frameworks, cases, methods, brands, bundles -- one corpus, shared embeddings.
Counters. Every entry tracks retrieval_count (it showed up in search) and a quality-gated usage_count (it was cited in an answer that scored well). The gate is the move that prevents "popular" from being mistaken for "good." Usage feeds back into ranking.
Co-citation graph. When a quality-gated answer cites several entries together, every pair gains edge weight. Edges decay on a multiplicative half-life, so old habits fade unless they keep earning reinforcement. Pure SQL -- no LLM involved.
Dreaming. Weekly between-session jobs read the graph and add LLM synthesis where SQL can't: naming emergent clusters, consolidating memory, proposing prompt revisions.
Surface. The four MCP servers, the Telegram bot, a 20-question eval harness, and the public cockpit -- a four-tab view (Pulse / Map / Radar / Dossiers) where load-bearing entries literally grow bigger and any entity opens to a one-page dossier.
The Weekly Dream (~$1 per run)
Every Sunday at 04:00 UTC, while I sleep, a GitHub Actions workflow runs the loop: benchmark the agent against 20 held-out consulting questions → run a generative probe that synthesizes ~10 fresh questions from the week's ingestion (so the graph keeps seeing new corpus, not just the fixed benchmark) → decay old co-citation edges → find hot connected components and have a small model name them as dreamed clusters → write everything into a Dream Review queue.
Dreamed clusters are not facts -- they are weak proposals until reviewed. The Dream Review queue is where I accept, dismiss, or promote them. Two heavier dreams (memory consolidation and agent-prompt revision) run manually and always require a human-reviewed diff before applying.
Paper Bundles: The Editorial Layer
The paper firehose is allowed to stay large -- 2,800+ papers and growing daily. Bundles are the layer that says what counts: curated groups with a title, a rationale, member roles, and a review status. A dreamed cluster with strong evidence gets promoted into a bundle; a bundle is something I can hand to a client conversation. Curation on top of the firehose, not instead of it.
The Eval Harness: Closing the Loop
A 20-question held-out benchmark with weighted rubrics tests the agent end-to-end against the live KB. Scored traces are what drive the quality gate: only answers above threshold increment usage counters and reinforce co-citation edges. The same scores feed the instruction dream, which proposes the next version of the agent prompt from low-scoring traces. Quality measurement isn't a report -- it's the system's feedback signal.
Key Innovation: Tunable Search Thresholds
Most semantic search systems use fixed similarity thresholds. Field Kit makes it user-adjustable per search for different consulting moments:
| Threshold | Mode | Use Case |
|---|---|---|
| 0.3 | Ultra-broad discovery | "Show me anything remotely related" - cross-domain pattern hunting |
| 0.4 | Balanced discovery (default) | "Find interesting connections" - normal consulting research |
| 0.5 | Moderate precision | "Show me related work" - academic literature review |
| 0.6 | High precision | "Find exact matches" - duplicate detection |
Why This Matters
Traditional search:
"AI ethics" → AI ethics papers only
Discovery search (0.3-0.4):
"AI ethics" → Constitutional AI, service design principles, governance frameworks, alignment research, EU regulations
You want serendipity. The Constitutional AI paper (0.451 similarity) wouldn't show at 0.6 threshold, but it's exactly what a service designer needs for ethics work.
Real Production Usage
Scenario 1: Client Question on Edge AI
Without Field Kit (old way):
- 1. Google "edge AI research 2024"
- 2. Sift through blog posts and vendor marketing
- 3. Search Google Scholar for academic backing
- 4. Read 5-6 abstracts
- 5. Synthesize findings manually
Time: 30-45 minutes
With Field Kit (new way):
- 1.
search_trends("edge AI deployment", similarity_threshold=0.4) - 2. Get 8 relevant signals including "Efficient VLAs: Edge Deployment of Embodied AI"
- 3.
search_papers("edge AI efficiency") - 4. Get 5 academic papers with citation counts
- 5.
connect_signals([signal1, signal2, signal3])→ AI synthesis
Time: 3-4 minutes
Result: Better answer (academic + trend signals + synthesis), 10x faster, with source citations ready for slides.
Scenario 2: Pattern Recognition Across Projects
Context: Notice similar challenges across 3 different clients - all struggling with internal AI governance, no clear decision-making framework for AI tool adoption.
Action: add_trend() with title "Enterprise AI Governance Vacuum", analysis of pattern, strength "accelerating", category "policy".
Future value: Next client with similar challenge → search finds this pattern → reference 3 past cases → faster diagnosis, better recommendations.
Compound returns in action.
Technical Foundation
Stack Choices
- Supabase: PostgreSQL + pgvector
Managed Postgres with vector extensions, sub-2s search
- MCP Servers: Python + FastMCP
Anthropic's official MCP spec, fast iteration
- Embeddings: OpenAI text-embedding-3-small
Best cost/performance, $0.02 per 1M tokens
- Interface: Claude Desktop + Telegram Bot + Claude Code
Desktop, mobile, and CLI access via MCP and SSE bridge
Performance Metrics
- • Search latency: <2s (embedding + vector search + formatting)
- • Ingestion speed: 2-3s per item (arXiv metadata)
- • Batch processing: 50 items in <60s (RSS feeds)
- • Cost per query: $0.00002 (embedding only)
- • Current scale: 6,690 items across 8 content types
- • Theoretical capacity: 100,000+ items (pgvector scales to millions)
- • Security: Row-Level Security on all tables
Data Pipeline
Sources → Claude Filtering → Embedding Generation → Supabase (pgvector) → Semantic Search Automated Ingestion (GitHub Actions - runs while you sleep): 1. arXiv RSS monitor: Daily scan for new papers in AI/ML categories 2. Trend RSS monitor: Scheduled scan of 9+ feeds (TechCrunch AI, VentureBeat, MIT Tech Review, etc.) 3. Claude Sonnet filters for consulting relevance 4. Auto-extract: title, analysis, strength, category, tags 5. Generate embedding → Store in Supabase with full metadata 6. Available for search immediately Manual Ingestion: - parse_newsletter: Paste newsletter content → extract 1-5 signals automatically - add_paper: arXiv ID or DOI → auto-fetch metadata via OpenAlex/Semantic Scholar - add_paper_manual: For papers not in indexed systems (title, authors, abstract) - web_research: Perplexity-powered live research with optional signal extraction Batch Ingestion: - Zotero/BibTeX pipeline: Export .bib → ingest_bib.py → auto-classify research areas - 13 category-specific batch scripts for seeding (RAG, agents, alignment, vision, etc.) Deployment: - Docker Compose with SSE transport (ports 8081-8084) - Telegram bot via MCPBridge (dynamic tool discovery + routing) Cost: ~$0.00001 per item for embeddings. 1000 items = $0.01.
Key Learnings
1. Selfish Software Works
Building for your own acute pain point produces better products than building for hypothetical users. You use it daily, notice every friction point, iterate immediately. No user interviews needed - you ARE the user. The tunable search threshold (0.3-0.6) came from real frustration: "Sometimes I want broad discovery, sometimes I want exact matches. Why force me to choose one?"
2. MCP Changes the Integration Game
MCP servers eliminate the "build a UI" bottleneck for internal tools. Before MCP: Build backend → Build API → Build web UI → Deploy → Maintain. With MCP: Build backend → Build MCP server → Use in Claude Desktop. Iteration speed: 10x faster. Focus on data and logic, not UI polish. When you DO want a web UI, the MCP server becomes your API. Nothing wasted.
3. Embeddings Are Cheap, Organization Is Expensive
Cost to embed 1000 items: $0.01. Time to manually tag and organize 1000 items: 20+ hours. Conclusion: Don't optimize for embedding cost. Optimize for capture friction. Field Kit approach: Embed everything, search semantically. No folders, no tags (optional tags for filtering, not for search).
4. Pattern Detection Requires AI Synthesis
Semantic search finds related items. That's retrieval. Pattern detection finds meta-trends across items. That requires reasoning. Solution: connect_signals tool uses Claude Sonnet to analyze 2-5 signals together and synthesize common themes, implications, emerging meta-trends, and strategic opportunities. Human-AI collaboration: You pick the signals, AI finds the patterns.
5. Knowledge Systems Have Compound Returns
Week 1: 20 signals, minor usefulness. Month 2: a few hundred signals and papers, frequently helpful. Today: 6,690 items across eight content types, with automated ingestion adding dozens daily -- answers most questions instantly, surfaces connections you'd never find manually, cross-references trends with regulations with academic evidence. The curve is exponential, not linear. The catch: past a few thousand items, growth alone stops being the interesting part. That's what forced the next learning.
6. A Knowledge Base That Learns Needs Sleep
Once the corpus outgrew what one person can hold in their head, the bottleneck shifted from capture to sensemaking. The answer wasn't a bigger search box -- it was giving the system a between-session life: counters that record what actually gets used, a co-citation graph that records what gets used together, and a weekly dreaming loop that names the patterns and queues them for review. Two design rules made it safe: gate every feedback signal on answer quality (popularity is not truth), and treat everything the system dreams up as a proposal until a human accepts it. Self-organization without those two rules is just drift.
Business Impact
For Consulting Work
- • 30-45 min research → 3-4 min (10x faster)
- • Better answers (trends + academic + synthesis)
- • Pattern recognition across projects
- • Continuous learning between engagements
For Client Deliverables
- • Faster workshop prep (frameworks library)
- • Stronger proposals (cite trends + research)
- • Better presentations (synthesized insights)
- • More confident recommendations
For Personal Growth
- • Capture insights without breaking flow
- • Discover unexpected connections
- • Build expertise systematically
- • Create proprietary IP (frameworks, patterns)
ROI Calculation
Development time: ~20 hours (MVP + iteration)
Time saved per week: ~2 hours (conservative estimate)
Break-even: 10 weeks
After 6 months: 50+ hours saved, plus compounding knowledge advantage
Current Scale
All tables secured with Row-Level Security. Automated ingestion via GitHub Actions (arXiv daily, RSS scheduled). The system grows while you sleep.
Roadmap & Evolution
Phase 1: Core Intelligence (✅ Complete)
- ✅ trend_monitor MCP server with 18 tools
- ✅ 267 trend signals (AI tech, sustainability, policy, service design, business models)
- ✅ 216 academic papers (frontier models, RAG, agents, alignment, multi-agent systems)
- ✅ RSS feed automation with Claude filtering
- ✅ Semantic search with tunable thresholds (0.3-0.6)
- ✅ Pattern detection via connect_signals
- ✅ Translation pipeline (Swedish → English)
- ✅ Supabase + pgvector infrastructure with RLS
- ✅ Claude Desktop + Claude Code integration
Phase 2: Extended Intelligence (✅ Complete)
- ✅ knowledge_base MCP server (11 tools: frameworks, cases, methods, stats)
- ✅ Perplexity integration for live web research with signal extraction
- ✅ Regulations table with 10 provisions (EU AI Act, GDPR, NIS2)
- ✅ analyze_regulatory_impact tool (use-case-specific impact assessment)
- ✅ Newsletter parsing (paste content → auto-extract signals)
- ✅ Paper full-text retrieval via ar5iv HTML conversion
- ✅ GitHub Actions automation (arXiv RSS daily, trend RSS scheduled)
Phase 3: Consulting OS (✅ Complete)
- ✅ market_researcher MCP server (11 tools: brand analysis, competitive intel, stats)
- ✅ Merger with agentTeamMarketResearcher into unified system
- ✅
search_all-- unified semantic search across trends, papers, regulations, brand reports, frameworks, and cases - ✅ Cross-domain linking (brands ↔ trends, papers ↔ signals, regulations ↔ signals)
- ✅ Row-Level Security on all tables
Phase 4: Multi-Interface & Deployment (✅ Complete)
- ✅ Telegram bot with Claude Sonnet agent loop and MCP bridge
- ✅ Docker Compose deployment with SSE transport (ports 8081-8084)
- ✅ MCPBridge for dynamic tool discovery and routing across servers
- ✅ Stats tools added to all servers (get_trend_stats, get_kb_stats, get_market_stats)
- ✅ Manual paper ingestion (add_paper_manual) for non-indexed sources
- ✅ Zotero/BibTeX batch ingestion pipeline with auto-classification
- ✅ Flexible research areas (dropped CHECK constraint, free-text with kebab-case)
- ✅ 4 new epistemology research domains (ai-epistemology, social-epistemology-ai, ai-education, ai-democracy)
Phase 5: The Self-Organizing Layer (✅ Complete)
- ✅ Usage counters with quality gating (retrieval vs. cited-in-a-good-answer)
- ✅ Co-citation graph with multiplicative half-life decay
- ✅ Weekly dreaming workflow: benchmark → generative probe → decay → cluster naming → Dream Review (~$1/run)
- ✅ Paper bundles as the curated editorial layer over the paper firehose
- ✅ Dream Review queue: accept / dismiss / promote dreamed proposals
- ✅ 20-question eval harness with rubric scoring, wired into the feedback loop
- ✅ Public cockpit at /field-kit -- four tabs (Pulse / Map / Radar / Dossiers): live stats, force-directed graph, AskBox agent, and entity dossiers for orgs and every corpus node
- ✅ Three-site deployment: local stdio, Hetzner VPS + Telegram bot, Mac mini research agent
What's Next
Edge Evidence Drawer
Every edge in the graph should show the reason it exists: which AskBox thread cited both entries, which dream probe reinforced the pair, which bundle membership connects the evidence. Provenance for connections, not just nodes.
AskBox Trace Overlay
Clicking an AskBox thread highlights the retrieved and cited nodes in the graph -- making actual use visible, not just archive structure.
"What Changed" Weekly Delta
A weekly view of new clusters, repeated questions, unbundled high-use papers, stale dream items, and emerging contradictions -- the organism's pulse, readable at a glance.
Graph Action Queue
Turn exploration into next actions: review this dreamed cluster, promote this bundle, write a field note, archive this noisy source, mark this edge as useful or noise.
Explore More
Status: ✅ 4 MCP servers, 70+ tools, 6,690 items, Telegram bot, weekly dreaming loop -- in daily use
Timeline: 8 weeks from idea to Consulting OS; the self-organizing layer grew over the months since
Repository: Private (sjobergfredrik/field-kit)
Deployment: Docker Compose + GitHub Actions for daily ingestion. Grows while you sleep.